
Squirreling: a new SQL engine for the web
Hyperparam is built on three bets: first, there’s a goldmine of information in LLM data — e.g. LLM chat logs or LLM training data. Second, people need tools to understand this data. And third, the browser is the only place to build modern interactive data tools. Over the past year, we’ve built a browser-native tool without a “classical” backend server that helps users transform and analyze massive LLM datasets. One of the core functionalities is the ability to extract structured information at scale with the use of AI.
Now comes the challenge. Hyperparam’s users end up with massive datasets with large text-blobby columns such as chat logs and structured columns with labels, scores, or other, more classical, structured information. Users need the ability to query over this data in the browser in an AI native manner. The only AI-friendly language to do this with is SQL, but there’s no SQL engine built natively for the browser that’s fast enough, low memory enough, or async enough to meet Hyperparam’s standards for interactivity.
So I did what all engineers do: I built Squirreling, a ~9 KB (minified and gzipped) SQL engine with zero external dependencies. It achieves instant startup and constant memory usage for streaming queries.
I made my first commit on November 15th; open-sourced it on November 22nd, and had it live in Hyperparam on November 26th. This would never have been possible with only one person and in such a short timeframe without AI.
Drawbacks of WebAssembly for SQL engines
To understand why existing browser-based SQL engines struggle with interactive data exploration, it helps to examine how they’re built. Tools like DuckDB-Wasm compile a full analytical SQL engine to WebAssembly so it can run inside the browser. But database engines relying on WebAssembly to run in the browser face inherent limitations:
- Large footprint: DuckDB-Wasm, for instance, exceeds 4MB, which adds to processing times.
- Synchronous execution model: This limits true streaming execution.
- Differences in memory types: WebAssembly’s linear memory model is separate from JavaScript’s heap memory, which requires data copying at boundaries.
In practice, this shows up as noticeable startup times before queries can run, delayed time-to-first-result, and execution behavior that prioritizes throughput over interactivity. Queries run to completion before yielding results. And if you wanted to have derived columns or user-defined functions (UDFs), there’s no way to connect DuckDB-Wasm with async API calls such as LLMs. This makes existing SQL engines less than optimal for exploratory workflows that depend on fast, incremental feedback.
How Squirreling fundamentally differs from existing SQL engines
Squirreling emerged as a response to the simple question: what happens if you design a SQL engine for the browser first, instead of adapting a server-oriented database to run there?
Starting from that premise leads to a different set of design choices than those made by existing solutions:
- Async-native execution: Squirreling relies on JavaScript’s AsyncGenerator protocol throughout, resulting in streaming query results and a responsive UI.
- Late materialization via lazy cells: Table cells are represented as async functions and are only evaluated when accessed, which minimizes expensive operations.
- Pluggable data sources: The AsyncDataSource interface decouples query execution from data retrieval, allowing data sources to only return the specific rows and columns a query requires.
These design choices are reflected throughout Squirreling’s architecture, shaping how queries execute, how data is retrieved, and how work is scheduled.
Squirreling’s architecture
Let’s examine the key parts of Squirreling’s architecture that make these design choices concrete.
Late materialization
Squirreling delays computing column values until the query needs them. Expensive operations only run on cells that survive earlier stages such as filtering, sorting, and limiting.
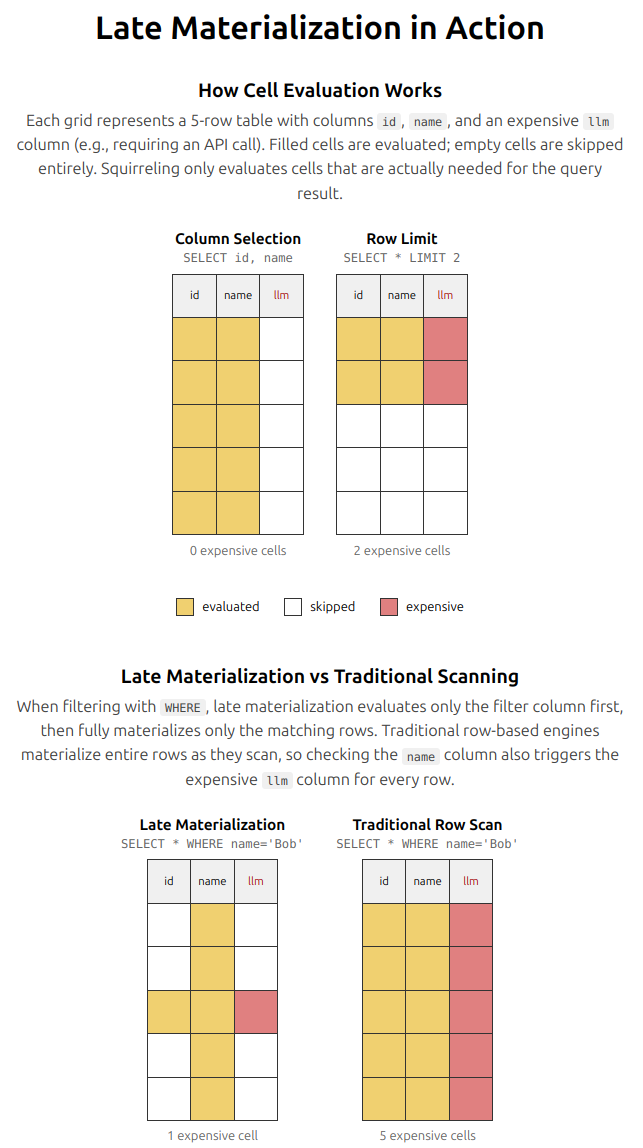
By delaying materialization, Squirreling executes joins over minimal projections and effectively inherits the asymptotically worst-case-optimal behavior of modern join algorithms, only materializing payload columns for rows that survive the join. [1]
Execution model
Squirreling distinguishes between streaming and buffered paths based on query characteristics:
- The streaming path is used for queries without ORDER BY, GROUP BY, or aggregates. It achieves constant data coverage regardless of the size of the dataset. It yields one input row, one output row, and a small amount of data that satisfies the limit query.
- The buffered path is used for queries with ORDER BY or GROUP BY; however, late materialization options are still implemented, and LIMIT is applied before projection. Squirreling buffers the rows first and only evaluates those columns that are required for the current stage of the query.
Query processing
Squirreling parses SQL into an AST and executes against the AST directly without a separate planning phase. This simple system avoids heavy planning overhead and allows execution to stay incremental and async. It fits the browser environment, where responsiveness matters more than deep cost-based optimization.
This AST-driven, async, late materialization model applies even to complex queries. Joins are executed directly from the AST, yielding an async and streaming result. They can stop early in the event LIMIT is applied and don’t force evaluation of columns. Columns are treated independently and evaluated individually and lazily, deferring expensive columns until required.
Module footprint
Squirreling is written in pure JavaScript with zero runtime dependencies. The complete library — consisting of the parser, executor, and all built-in functions — compiles to ~9kb (minified and gzipped). That’s 500x smaller than DuckDB-Wasm’s 4.5 MB binary.
This small footprint offers the following benefits:
- Instant startup: Because there’s no WebAssembly compilation delay, Squirreling is ready to execute queries immediately after the JavaScript loads.
- Embeddability: Squirreling can be bundled into applications with almost no impact on size.
- Edge deployment: Squirreling’s small size enables deployment in serverless edge functions or service workers — environments that typically can’t host databases at all.
Squirreling: a browser-native SQL engine
These architectural choices follow logically from treating the browser as the primary execution environment for interactive exploration. The result is a browser-native SQL engine with a set of properties that shape how queries run:
- Immediate, incremental query execution in the browser. Queries start producing results as soon as execution begins, with rows and cells streaming as they’re ready. Users can inspect partial output, refine queries, or stop execution without blocking the UI or waiting for full execution.
- Explicit control over when expensive work runs. Columns are evaluated only when referenced, and LIMIT and ORDER BY act as cost controls as well as query clauses. Expensive operations run only when required, which allows execution to stop early to avoid unnecessary computation.
- Lightweight, backend-free exploration over asynchronous data. Squirreling runs entirely client-side as an open-source library, with no backend, account setup, or loading flows. It supports interactive querying over asynchronous data sources, including cloud-native formats like Parquet, in a footprint of ~9KB (minified and gzipped).
Squirreling is available as an open-source library here: github.com/hyparam/squirreling
References
[1] Abadi, D. J., Myers, D. S., DeWitt, D. J., & Madden, S. R. (2007). Materialization Strategies in a Column-Oriented DBMS. In Proceedings of the 23rd International Conference on Data Engineering (ICDE) (pp. 466–475). IEEE.