
Simulated Personas, Real Insights: Using Snowglobe and Hyperparam to Stress-Test Conversational AI
Testing our Conversations Before we Go Live
Hyperparam is building an AI-assisted tool for working with large text datasets. The product includes a viewer for parquet (and csv and jsonl) datasets, and a data assistant chat. Before launching the product we wanted to anticipate problems that may crop up.
The fastest way there was to generate simulated data with realistic, diverse, edge-case conversations that exposed how our data agent behaved across user types and intents. Once we could generate this data we had a quick way to interrogate the simulation data set in order to slice, flag and transform the conversations into a usable data set for follow on fine tuning (or continued analysis).
Our setup: Snowglobe for simulation + Hyperparam for exploration
Plan:
-
Simulate 10 realistic personas and conversations using Snowglobe.
-
Explore and transform that dataset interactively with Hyperparam.
-
Isolate conversations where the agent recommended using Python versus general analytical queries.
-
Prepare the subset for evaluation or fine-tuning.
Step 1: Generate Synthetic Conversations with Snowglobe
Snowglobe is a simulation engine for conversational AI teams. You define who your users are, what they want, and how they behave. Snowglobe auto-generates thousands of realistic interactions with your model or API endpoint. Think of it as a load test for reasoning or dialogue, not just latency. Snowglobe uses the information from an application description to create data that’s useful for your specific app. For this blog post, we created an application with the system prompt from Hyperparam. It’s long, but the short version looks like: “This chatbot allows users to chat with their data, pulling out insights and statistics. The data looks like this:
Define Your Personas
In our example, we’re simulating users of Hyperparam, a data exploration tool. We want personas that mirror the real user base data engineers, data analysts, and tinkerers with different levels of skill and temperament. To create personas like these, we can start with a “Simulation prompt”. For example, we can enter a simulation prompt like “Users are data engineers, scientists, and analysts ask questions about their data.”
This prompt results in personas like follows. These personas vary in objective, tone, and style.
personas:
- name: "Hands-On Data Explorer"
description: Loves examples, learns by doing.
- name: "Skeptical Analyst"
description: Double-checks every step, asks 'why'.
- name: "Product Engineer"
description: Wants quick, applied answers.
- name: "Aha Moment Seeker"
description: Prefers conceptual explanations.
...
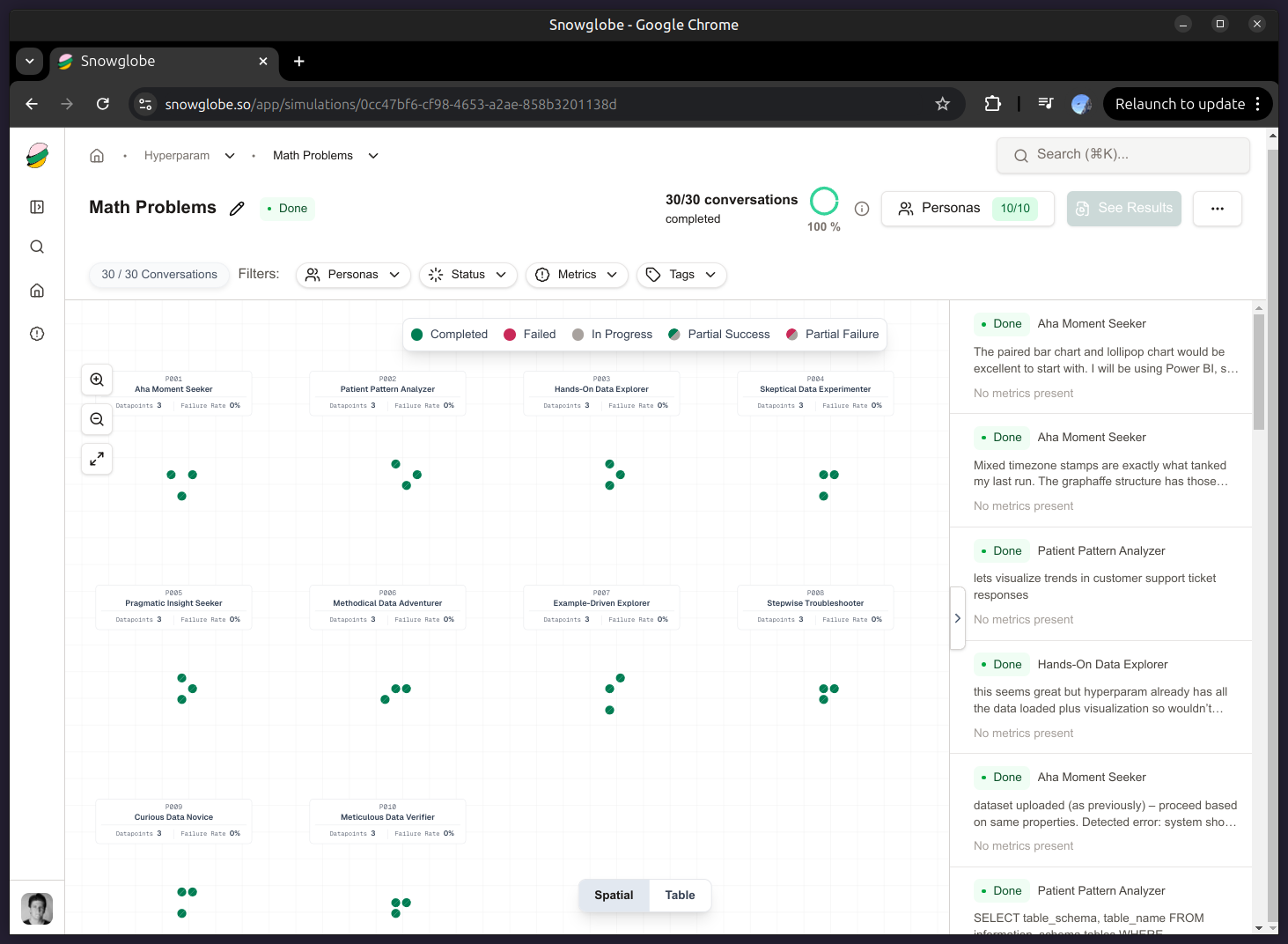
Configure Conversation Scenarios
This provides us with conversation templates tied to our product use cases:
scenarios:
- topic: "data analysis"
prompt: "How can I explore this dataset for outliers?"
- topic: "python vs sql"
prompt: "Should I use Python or write an analytic query?"
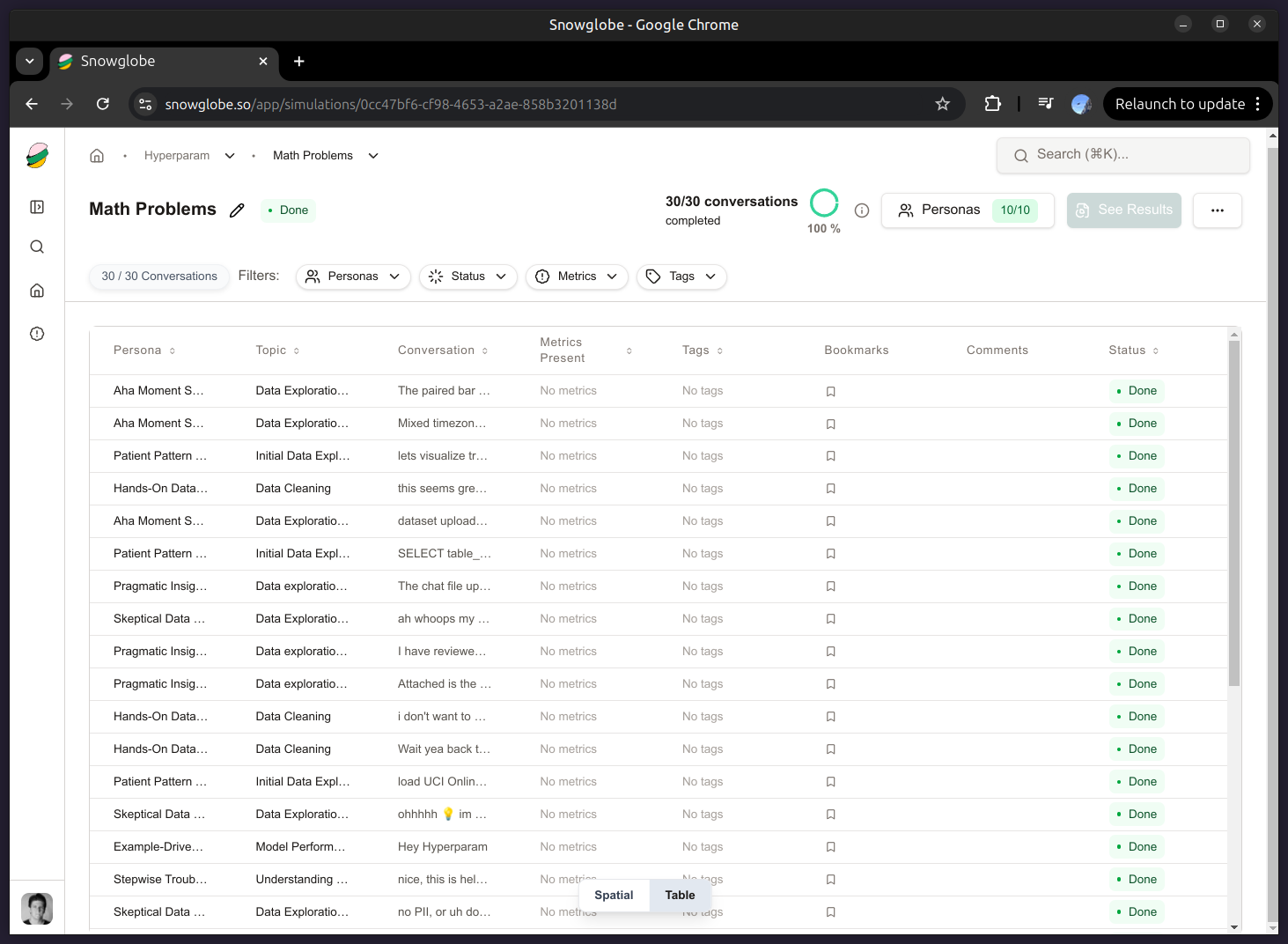
Snowglobe will orchestrate multi-turn dialogues between each persona and our model endpoint, generating text logs, metadata, and structured output (JSONL).
When the run completes, we have a dataset with 10 personas × 200 conversations each — 2000 total dialogues, complete with role labels, timestamps, and message-level metadata.
Step 2: Explore the Dataset in Hyperparam
Hyperparam is an interactive, browser-based dataset explorer purpose-built for ML workflows. It opens local or remote Parquet, JSONL, CSV files instantly and lets you filter, transform, and visualize data directly: no heavy Jupyter notebooks required.
Drop file directly in the explorer
Hyperparam renders the dataset in an interactive table. You can scroll through conversations, inspect columns like persona, topic, or assistant_message, and even preview message trees. Conversation view allows for easy visual exploration.
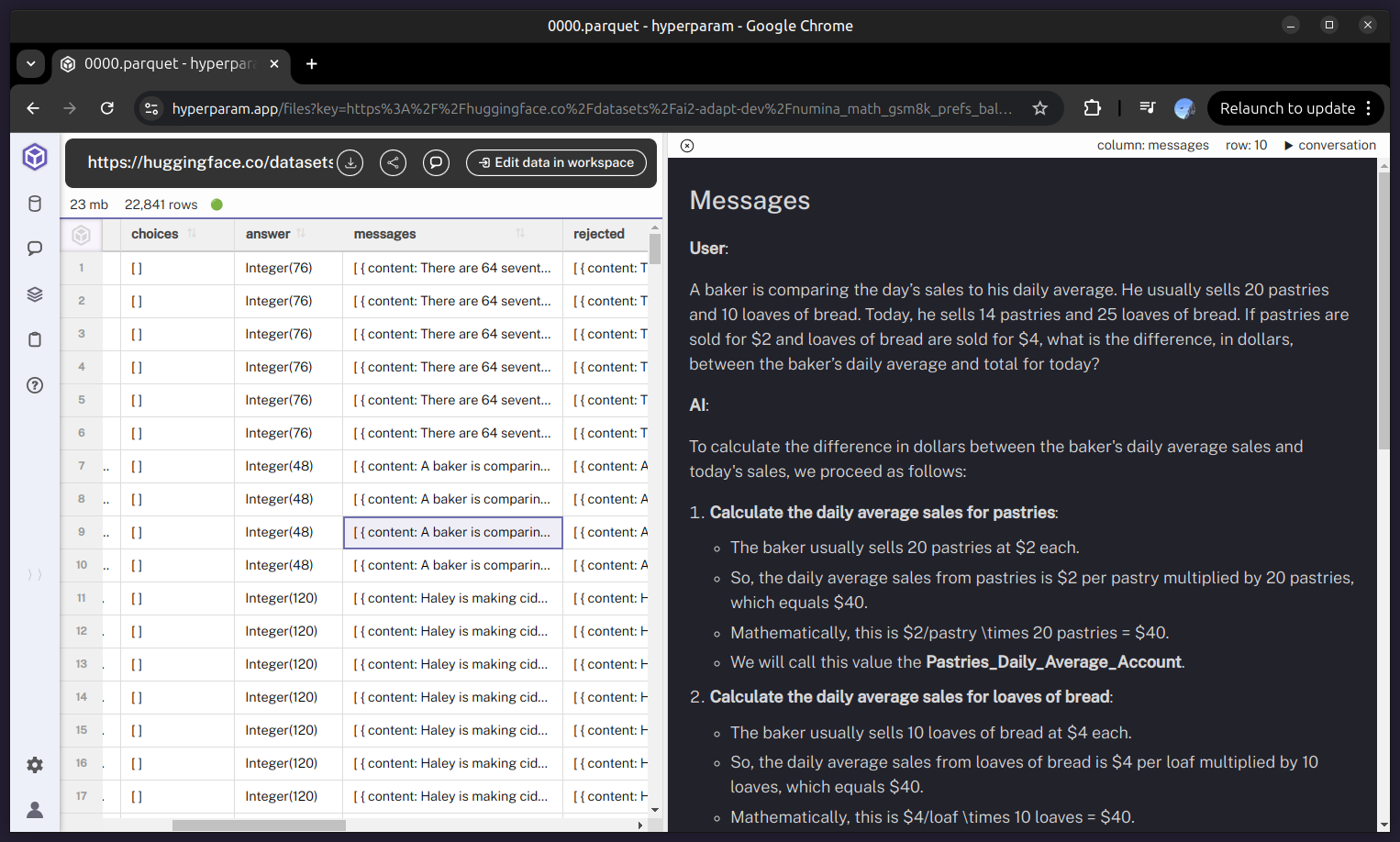
One of the things we noticed right off the bat was that sometimes a user would ask a question and the model would suggest leaving the product and that they use a python script instead. This is not what we want. Sometimes though, the user asks a question that genuinely need to be done off-platform. What we’d really like to find is the conversations that could have been solved on-platform, but instead the model recommended python.
Step 3: Flag Conversations with Hyperparam
Now we want to detect when the assistant recommended Python code vs analytic query language in its replies.
In Hyperparam, you can do this with the hyperparam chat: a prompt-based operation that adds a new computed column.
Prompt: “Add columns: flag when a model suggests the user run python themselves, or makes a general analytic-style query instead of a transformation or filtering like we expect.”
The data agent runs across all sample rows, and decides to create two new boolean columns:
- suggested_user_python: true/false
- is_analytics_query: true/false
This single operation converts raw chat logs into labeled data.
Step 4: Filter, Export, and Iterate
After inspecting the two new columns, we wanted to extract the samples where it suggested using python but not as a general analytics query. This is our proxy for things our data-agent should be able to do but for some reason did not.
By visually inspecting the data we notice:
-
“Hands-On Data Explorer” and “Skeptical Analyst” personas trigger Python examples more frequently.
-
“Pragmatic Insight Seekers” get concise analytic answers.
-
Conversations recommending Python also tend to have longer message chains (higher cognitive load).
The data set of [suggested_user_python=true && is_analytics_query=false] is good for further fine-tuning our data agent as examples of where we should have a suggestions but did not.
Step 5: Why This Workflow Matters
The combination of Snowglobe + Hyperparam closes a crucial loop for conversational AI teams:
| Stage | Tool | Outcome |
|---|---|---|
| Simulation | Snowglobe | Synthetic but realistic data across personas |
| Exploration | Hyperparam | Fast, visual filtering and labeling |
| Transformation | Hyperparam | LLM-assisted column creation |
| Iteration | Both | Repeat, evaluate, fine-tune |
This pipeline lets teams:
-
Build evaluation datasets before collecting real user data.
-
Debug reasoning patterns in synthetic interactions.
-
Scale up diverse conversational contexts without manual labeling.
-
Quickly explore and interact with the data sets.
Closing Thoughts
Simulation is the new data collection.
When you can generate, label, and filter conversation data quickly, interactively and with precision, you gain the power to test your agent’s reasoning loops and UX outcomes before they ever reach a customer.
Snowglobe gives you the synthetic user base. Hyperparam gives you the interactive microscope.
Next steps:
-
Try snowglobe.so to generate your own synthetic conversations.
-
Explore the data instantly with hyperparam.app.