
Hyperparam: How Browser-Based Tools Will Re-Shape AI
What is the key to building the most advanced AI models? Data quality.
Everyone wants better AI models: smarter, cheaper, and with style. How does one achieve that? Whether you’re a mega-scale AI company, or a small enterprise team, the only real lever for making better models is to construct a better training set.
How do you build a better training set? This is a question that has always been one of the most challenging, and labor-intensive parts of the data science process.
Why is data cleaning and data understanding so time-consuming? Because current tools often miss three key capabilities: 1) should enable very fast free-form data exploration by the user, which is key to finding insights in your data, 2) use AI models to assist looking at huge volumes of data that would be impractical for a person, and 3) should be simple to run locally in the browser and not depend on complex services and data pipelines. Instead, most tools are built around Python, arguably the worst language for creating modern, compelling UIs and tools. This might seem controversial, but think about what is the most common interface for python? Jupyter Notebooks. Notebooks are great for iteration and experimentation, but they are extremely weak when it comes to interactive data exploration. If you’ve ever tried to open a parquet file (the most common format for modern ML datasets) in a notebook it looks like this:
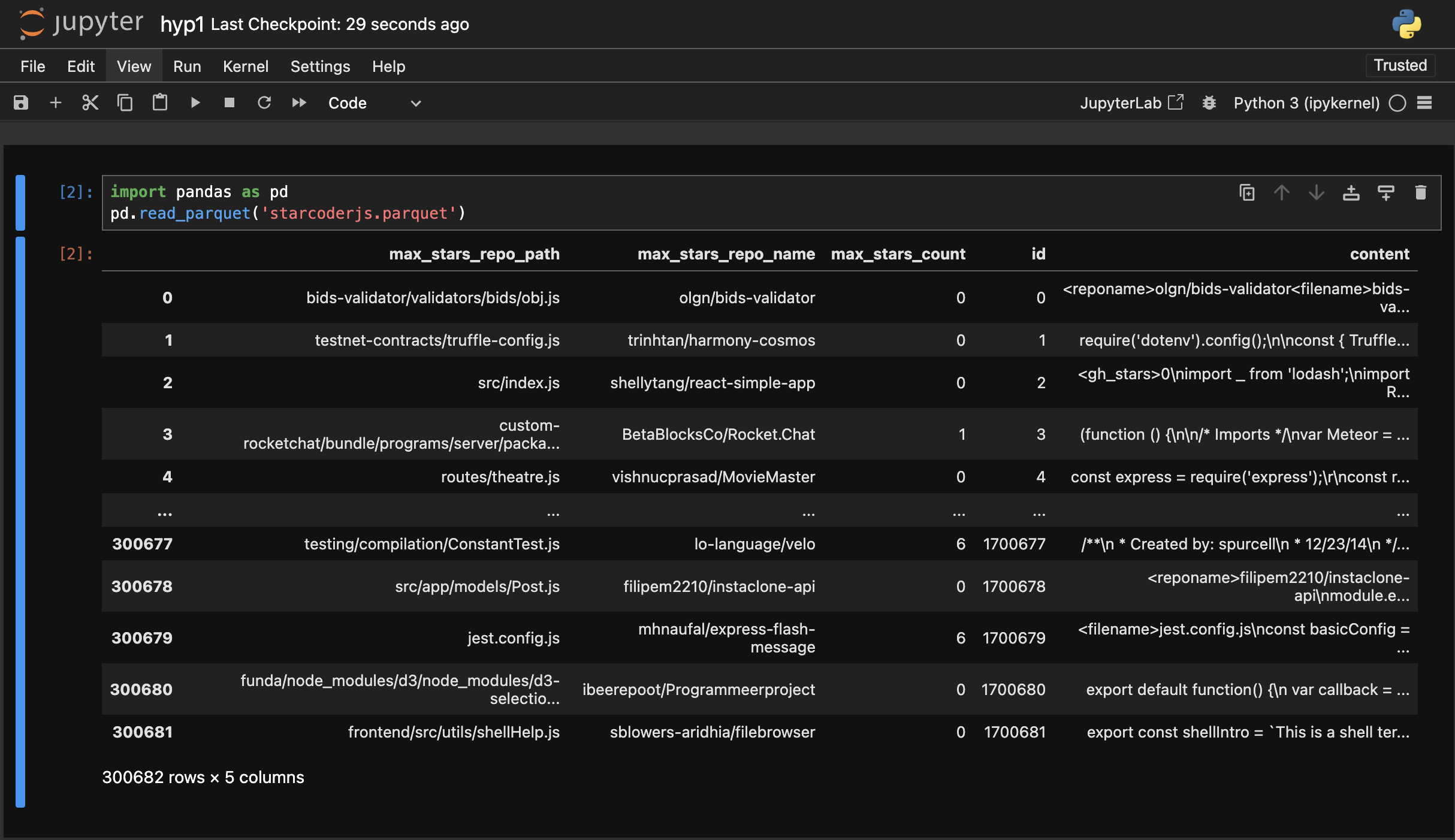
This table is practically useless. You can’t paginate to the next set of rows. You can’t even see the entire data in a cell (which in this case is an entire github source file). So how are you supposed to get an intuitive sense of your data if you can’t even see it?
Can we do better? If you want to build a highly performant user interface, there is only one choice: JavaScript. The browser is the only place for building modern UIs.
The problem is that ML datasets are massive (often multiple gigabytes of compressed text data), so it’s not obvious if it’s even possible to work with large scale datasets in the browser. However, by using modern data formats like Apache Parquet, and clever frontend engineering, it is in fact possible to work with massive datasets directly in the browser.
Aside: Apache Parquet files are a column-oriented data structure that contains a built-in index. This allows tools like hadoop and duckdb to efficiently query parquet datasets without having to retrieve all the data. Furthermore it allows doing these queries without a server, simply by putting the parquet files in a storage service like S3. What if you could do this same trick in the browser, and pull in just the data needed to render the current view. Hello Hyparquet.
Hyparquet is a new JavaScript parquet parser which can efficiently query against parquet files stored in the cloud. This enables the creation of a new type of client-side only parquet data viewer which is significantly faster than anything that could be done with a server.
The goal here is to get data engineers to look at their data 👀 Anyone who has worked with data for a model before knows that looking at your data is the key to understanding the domain you’re trying to model, and it is virtually impossible to do good data science without looking at your data. Looking at your data is the easiest way to find data and model issues, and is a constant source of ideas of how to improve them.
This is one of the core workflows in data science: build a model, see what data was correctly or incorrectly modeled, fix the data and/or the model, and repeat. This is a repeatable, teachable process! And if it can be taught to a human data scientist, why can’t it be taught to a model to assist?
Can you use a model to assist with dataset curation? The challenges are two-fold: 1) How do you leverage human expertise to express what you want from the model? 2) These datasets are huge, so the cost of running a model across all the data is expensive.
You need the human in the loop to express their intent for the data. There is not just one definition of “good” versus “bad” data. What matters is the question “is this data useful for the model I’m trying to build?” This is where the UI comes in as a way to allow the user to look at the data, and use the data to express their intent.
As for the cost, we are entering a new era of LLMs where for the first time it is affordable to do dataset-scale inference in which you run an entire dataset through a model to help filter and label data. In 2023 it cost $5,000,000 USD to process 1 trillion input tokens with a sota model (gpt-4-turbo). In 2024 it cost $75,000 USD to process 1 trillion input tokens with a similar model (gpt-4o-mini). This trend will continue to make dataset-scale inference accessible to model builders. Model-based quality filtering has already been used by Meta to filter the training set for llama3 using labels generated by llama2 [1].
We’re entering a new era in which dataset-scale inference and interactive, browser-based data exploration will define how AI models are built and refined. By combining efficient data formats, high-performance JavaScript interfaces, and affordable AI-based annotations, teams can finally put data quality front and center without prohibitively high costs or clunky workflows.
The future belongs to those who seamlessly blend human expertise with AI-assisted insights—an approach that makes data cleaning faster, more intuitive, and ultimately, far more effective in powering the next generation of advanced AI models.